- Published on
Benchmarking Python and Rust web servers
- Authors

- Name
- Jonas Vetterle
- @jvetterle
This article is part of a series in which we compare implementations of a simple web server in different programming languages. If you're interested, check out the actual implementations used in this article in Python and in Rust. And if you just want to see the code, you can find it on my GitHub.
Axum beats Rocket beats FastAPI
In case you're not interested in the details and just want to know the results, here they are.
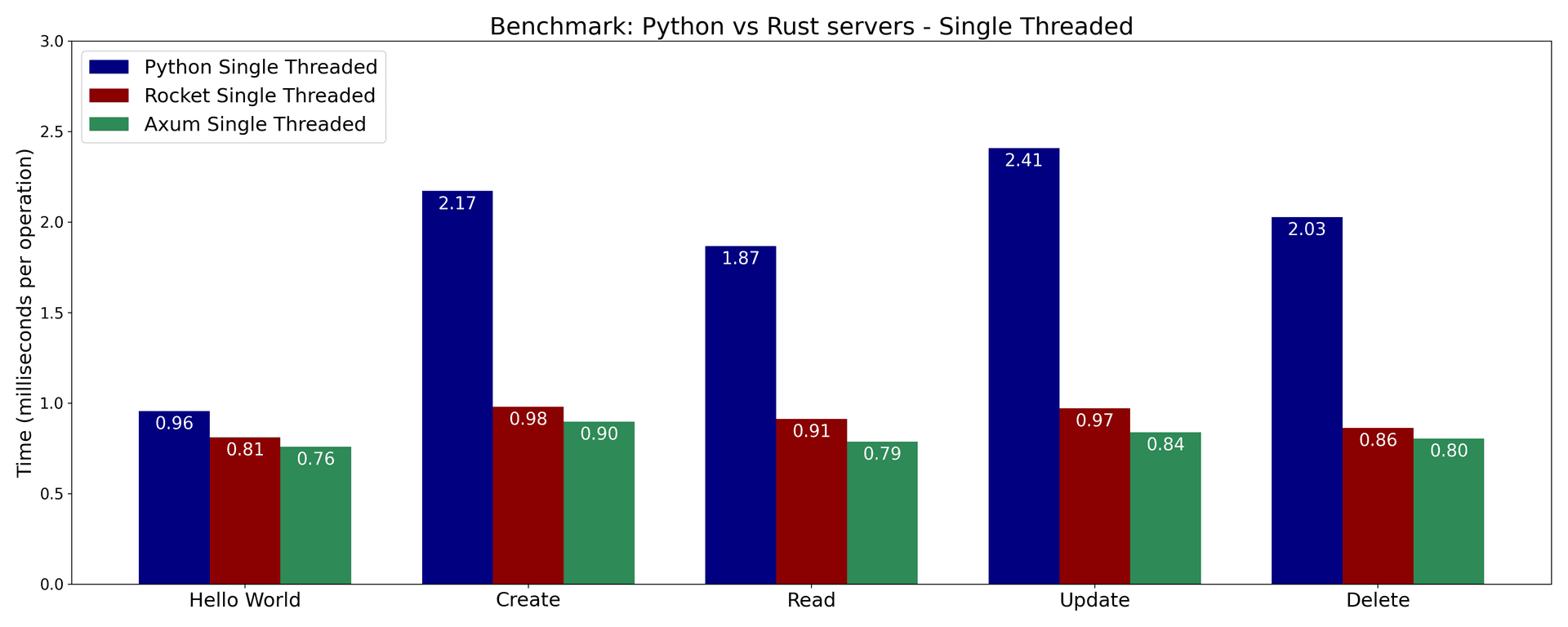
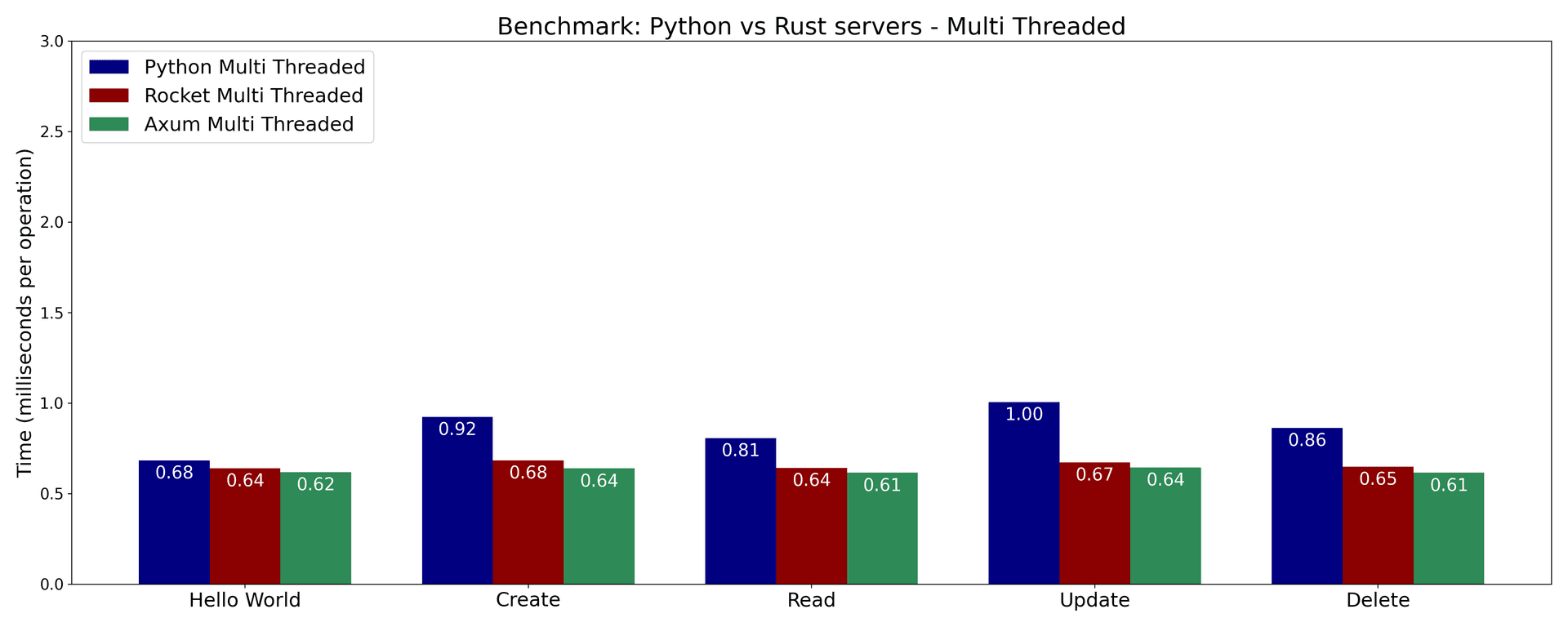
- In our simple web server benchmark, it seems like Rust servers are faster than Python servers. This is unsurprising given that Python is generally not known for its speed.
- Axum (Rust) is fastest across the board, and Rocket (Rust) takes second position in most cases.
- FastAPI (Python) is unsurprisingly the slowest of the three, especially the end points that interact with a database.
- This seems to suggest that FastAPI itself doesn't add much overhead for simple end points. However, when it comes to end points that interact with a database, the overhead of SQLAlchemy becomes more apparent.
Here is an overview of the different implementations:
| Web server | DB management | |
|---|---|---|
| Python | FastAPI | SQLAlchemy |
| Rust | Rocket | Diesel |
| Rust | Axum | Diesel |
What we are benchmarking
If you take a look at the Python and Rust implementations, you'll see that we built the following:
- An API server that could be the backbone of a very simple todo app. It has the following end points:
- a
GETroute that returns a "Hello, World" message. GET,POST,PUTandDELETEroutes to manage tasks.
- a
- A file-based SQLite database with a single table to store tasks.
- Connection pooling and write ahead logging (WAL) enabled for SQLite to improve performance under heavy load.
- Each server is run with 2 workers.
As you can see, the setup is very simple but not exactly minimal. For example, connection pooling and WAL are not strictly necessary for a simple benchmark like this one. However, for example WAL is enabled by default by Rocket, and I found that if I didn't enable it in axum, there would be "DB locked" errors when running the benchmarks. So I decided to also enable it in the FastAPI and axum implementations to keep things consistent. FastAPI didn't fail without it, but it gave it a nice performance boost.
Caveats
The results of this benchmark should be taken with a grain (or a rather large portion) of salt.
- I ran the benchmark on my local machine, which has all kind of stuff running. Running it in an isolated environment would make the benchmark more meaningful
- SQLite is a widely used database, but the main reason I used it in this benchmark is because it's easy to set up. In a real-world scenario, something like postgres can be a better choice, as it's more scalable and performant.
- For the concurrent benchmark we should choose a database that can actually handle concurrent requests better than SQLite.
- No benchmark is perfect or complete. There are many more frameworks both in the Rust and Python ecosystems that could be tested.
The benchmark script
I wrote a little benchmark script that measures the time it takes to make a certain number of requests to the different endpoints on each server. Each endpoint is hit 10,000 times, and I measure the time it takes to complete all requests divided by the number of requests to get the average time per request.
The script does this once in single-threaded mode and once in multi-threaded mode. The multi-threaded mode is intended to test which server can handle concurrent requests the best. I'm testing with 10 threads, which is a bit arbitrary, but I think it's a reasonable number for a simple server like this.
Here is the script:
import concurrent.futures
import json
import time
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
BASE_URL = "http://localhost:8000"
ITERATIONS = 10000
PARALLEL_REQUESTS = 10
# Create a session with connection pooling and retries
session = requests.Session()
retries = Retry(total=1, backoff_factor=0.1, status_forcelist=[500, 502, 503, 504])
adapter = HTTPAdapter(max_retries=retries, pool_connections=100, pool_maxsize=100)
session.mount("http://", adapter)
def hello_world():
return session.get(f"{BASE_URL}/")
def create_task():
response = session.post(f"{BASE_URL}/tasks", json={"name": "Test Task", "done": False})
response.raise_for_status()
return response.json()["id"]
def read_task(task_id):
response = session.get(f"{BASE_URL}/tasks/{task_id}")
response.raise_for_status()
def update_task(task_id):
response = session.put(f"{BASE_URL}/tasks/{task_id}", json={"name": "Updated Task", "done": True})
response.raise_for_status()
def delete_task(task_id):
response = session.delete(f"{BASE_URL}/tasks/{task_id}")
response.raise_for_status()
def prepare_tasks():
task_ids = []
with concurrent.futures.ThreadPoolExecutor(max_workers=PARALLEL_REQUESTS) as executor:
futures = [executor.submit(create_task) for _ in range(ITERATIONS)]
for future in concurrent.futures.as_completed(futures):
task_id = future.result()
if task_id is not None:
task_ids.append(task_id)
return task_ids
def cleanup_tasks(task_ids):
with concurrent.futures.ThreadPoolExecutor(max_workers=PARALLEL_REQUESTS) as executor:
futures = [executor.submit(delete_task, task_id) for task_id in task_ids]
concurrent.futures.wait(futures)
def benchmark_operation(operation, single_threaded, task_ids=None):
if single_threaded:
start_time = time.perf_counter()
for task_id in task_ids or range(ITERATIONS):
operation(task_id) if task_ids else operation()
end_time = time.perf_counter()
else:
start_time = time.perf_counter()
with concurrent.futures.ThreadPoolExecutor(max_workers=PARALLEL_REQUESTS) as executor:
futures = [
executor.submit(operation, task_id) if task_ids else executor.submit(operation)
for task_id in (task_ids or range(ITERATIONS))
]
concurrent.futures.wait(futures)
end_time = time.perf_counter()
return (end_time - start_time) / ITERATIONS * 1000 # Average time per operation in milliseconds
def run_benchmarks():
benchmarks = [
("Hello World", hello_world, None),
("Create", create_task, None),
("Read", read_task, prepare_tasks),
("Update", update_task, prepare_tasks),
("Delete", delete_task, prepare_tasks),
]
results = {}
for name, operation, setup_function in benchmarks:
task_ids = setup_function() if setup_function else None
# Benchmark single-threaded
single_threaded_time = benchmark_operation(operation, True, task_ids)
results[name] = {"single_threaded": single_threaded_time}
# Cleanup after single-threaded benchmark if necessary
if task_ids and name != "Delete":
cleanup_tasks(task_ids)
# Re-prepare tasks for multi-threaded benchmark if necessary
task_ids = setup_function() if setup_function else None
# Benchmark multi-threaded
multi_threaded_time = benchmark_operation(operation, False, task_ids)
results[name]["multi_threaded"] = multi_threaded_time
# Cleanup after multi-threaded benchmark if necessary
if task_ids and name != "Delete":
cleanup_tasks(task_ids)
# Print results
print(f"\nBenchmarking {name}:")
print(f" Single-threaded: {single_threaded_time:.6f} ms per operation")
print(f" Multi-threaded: {multi_threaded_time:.6f} ms per operation")
return results
def save_results(results, filename="benchmark_results.json"):
with open(filename, "w") as f:
json.dump(results, f, indent=2)
print(f"Results saved to {filename}")
if __name__ == "__main__":
print(f"Running benchmark with {ITERATIONS} iterations for each operation")
benchmark_results = run_benchmarks()
save_results(benchmark_results)
Discussion of results
Unsurprisingly, the multi-threaded benchmarks achieve better performance than the single-threaded benchmarks.
Also, largely unsurprisingly, the Rust servers outperform the Python server across the board.
Why is the FastAPI server slower than the Rust servers? One hypothesis is that the SQLAlchemy ORM adds some overhead. This could be bested by using raw SQL queries or a different ORM.
Another reason is probably that FastAPI/SQLAlchemy use a sessions-based model, whereas the Rust implementations work with connections directly. Sessions do add some overhead, because of the additional abstractions they provide like tracking object changes and handling transactions.
It may seem like the Rust implementations provide a huge performance boost when it comes to interacting with a database. For example in the single-threaded benchmark, the Axum server takes only 40% as much time as the FastAPI server.
However, keep in mind that we're working with a local server and database here where a single API request takes around 1 millisecond. In a real-world scenario, where the API and database are deployed on different servers, maybe even different regions, the latency can be on the order of hundreds of milliseconds. So any performance difference between the servers might be negligible in practice.
That's it for this benchmark - I hope you found it interesting. It's kind of what I expected - Rust is faster than Python. Does that mean I will never use Python for web servers again? That's not the conclusion I am drawing from this benchmark.
Python has great libraries and many developers are familiar with it. You will find help and resources for Python everywhere. In terms of pure development velocity, Python is ahead of Rust when it comes to building a REST API server. Part of the reason is that Python has a simpler syntax, and high level abstractions that make it easier to learn and use (at least in the beginning). It's also an interpreted language, so no need to compile the code every time you make a change.
Rust on the other hand comes with compile-time checks which will help you catch bugs early on. So in the long-term you might get benefits in terms of velocity by catching errors earlier and having just more robust code.
There are things Rust are unequivocally better at than Python, for example when it comes pure performance and concurrent programming. But in my opinion, building a REST API server is not one of them. Yes there is a small speed up according to this benchmark, but it's not a huge difference in practice because it will be dwarfed by the latency of the network.
With that, happy coding everyone!